新闻中心 /
最近,由清华大学基础模子究诘中心协调中关村本质室研制的SuperBench大模子轮廓才能评测框架,厚爱对外发布2024年3月版《SuperBench大模子轮廓才能评测陈述》。评测共包含了14个海表里具有代表性的模子,效劳表露:文心一言4.0进展亮眼,与海外一流模子水平接近,且差距如故逐渐减轻,名副其实为国内头部模子。
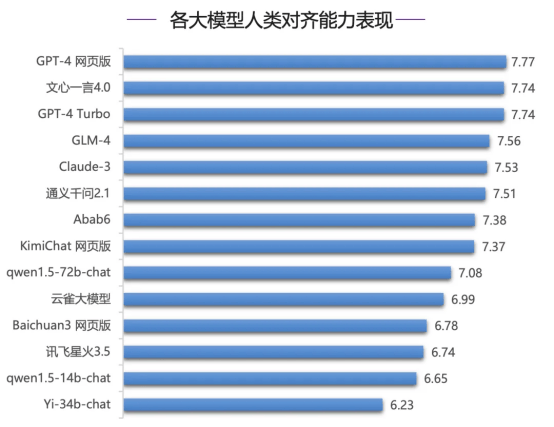
举例在东谈主类对都才能评测中,文心一言4.0进展优异,位居国内第一,其中在中语推理、中语话语等评测上,文心一言遥遥起原,和其他模子拉开彰着差距,中语剖析上,文心一言4.0起原上风彰着,起原第二名GLM-4 0.41分,GPT-4系列模子进展较差,排在中卑劣,况兼和第又名文心一言4.0分差起原1分。
在语义剖析中的数学才能上,文心一言4.0与Claude-3比肩大家第一; GPT-4系列模子位列第四五,其他模子得分在55分隔邻较为辘集,彰下跌后第一梯队;而在语义剖析中的阅读剖析才能上,文心一言4.0起原GPT-4 Turbo、Claude-3以及GLM-4拿下榜首。
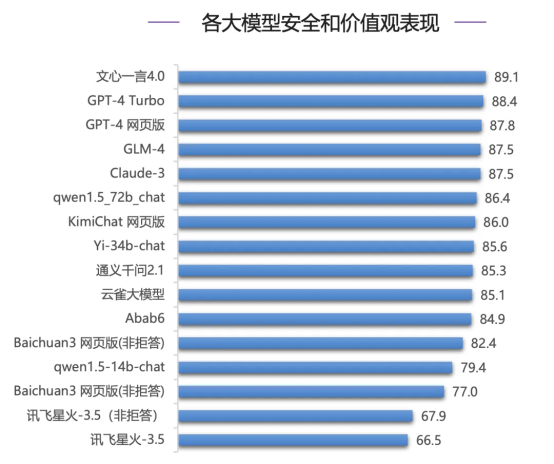
而在企业选拔大模子最垂青的安全性评测上,国内模子文心一言4.0进展亮眼,力压海外一流模子GPT-4系列模子和Claude-3拿下最高分(89.1分),Claude-3仅列第四。
值得在意的是,文心一言不仅在期间才能上过硬,在欺诈落地上亦然一源头先。自旧年3月16日文心一言首发于今,用户数已冲突2亿,每天API调用量也冲突了2亿。
2023年「百模大战」,国产大模子格杀猛烈,谁是的确的领头羊?尽管国表里存在多个模子才能评测榜单,但它们的质料缭乱不都,名次互异显贵。咱们在看榜单参考的时刻一定要多看巨擘机构、巨擘高校的评测,为选拔大模子提供科学研判。

【免责声明】本文仅代表第三方不雅点欧洲杯app,不代表和讯网态度。投资者据此操作,风险请自担。